Delay is the enemy of progress
—Widely attributed to Eliot Spitzer, American politician and attorney
Solution Train Flow
Solution Train Flow describes a state where a Solution Train delivers a continuous flow of valuable capabilities to the customer.
The SAFe Enterprise Solution Delivery competency guides how ARTs can work together with an aligned mission to build some of the world’s largest and most critical systems. This competency has proven effective in improving business outcomes for SAFe Enterprises building these systems.
But solution delivery at scale is complex and requires unprecedented cooperation between release trains, suppliers, customers, and stakeholders. The world relies on these substantial systems, and every delay is a lost opportunity to help those depending on them. This article describes how to provide a continuous flow of value delivery, even when building the world’s largest and most complex systems.
![]() Note: About the Flow Article Series
Note: About the Flow Article Series
SAFe is a flow-based system. As such, any interruptions to flow must be identified and addressed systematically to enable continuous value delivery. While flow-based guidance is embedded throughout SAFe, a special collection of eight articles directly addresses impediments to flow. These are Value Stream Management, Principle #6- Make value flow without interruptions, Team Flow, ART Flow, Solution Train Flow, Portfolio Flow, the extended Guidance articles Accelerating Flow with SAFe, and Coaching Flow.
Details
SAFe defines a set of eight flow accelerators that can address, optimize, and debug issues to achieve continuous flow at any level of the Framework. This article describes how Solution Trains can apply these eight accelerators to improve the flow of value for large and complex systems. Each accelerator is described in the sections below.
#1 Visualize and Limit WIP
Why it matters
Building big systems requires a lot of work. In response, it is common that the development process is overloaded with more work than can be reasonably accomplished in the time allotted. Excessive Work in Process (WIP) overburdens development leading to burnout, missed deadlines, cost overruns, and ultimately, poor economic outcomes.
What to do about it
Fortunately, managing WIP is a recognized and addressable problem. Common techniques include:
- Make all WIP visible. Solution Train WIP comes from two sources (Figure 1). The Solution Train Kanban system identifies and tracks new solution Capabilities implementation. In addition, the ARTs have work that arises locally to support their solution’s vision. Both sources add to the work in the development system. Seeing, understanding, and respecting both sources is the key to evaluating the entire system’s work volume and limiting it to improve throughput.

- Align work to available capacity. Solution Train leaders should understand their ART’s and suppliers’ capacities to ensure system throughput. The Solution Roadmap must typically be continually adjusted to align future work (new Epics and Capabilities) to the available capacity.
#2 Address Bottlenecks
Why it matters
It takes significant resources to build large solutions—people, supply chains, organizations, existing systems, and materials. To achieve the intended results, they all must work in concert. Bottlenecks must be identified and addressed continuously.
What to do about it
- Discover and address bottlenecks. There are many ways to uncover bottlenecks:
-
- Visualizing the WIP in the stages of the development pipeline
- Observing and surfacing the pain of delays and missed milestones
- Listening to development teams’ feedback about stresses and problems in the system
Events such as Inspect & Adapt also help proactively identify and address bottlenecks. However they are discovered, there are multiple ways to remediate them:
- Increase the capacity at the bottleneck. Increasing capacity at bottlenecks is an obvious first step. Address bottlenecks caused by insufficient knowledge or skills by employing additional teams or Shared Services, leveraging other suppliers, or creating more ‘T-shaped’ ARTs and teams to flex to the bottleneck activities (see Enterprise Solution Delivery). Bottlenecks caused by insufficient resources (lack of testing environments) or inadequate automation (manual build and integration steps) require proper investment to mitigate them.
- Move work around the bottleneck. Where bottlenecks persist, adjust the Solution Roadmap to focus on delivering value that does not have to work through bottleneck resources.
- Move work between suppliers. Ensure that contracts and internal governance rules permit teams to move the work freely to those with capacity. For example, confirm that governance rules allow everyone reasonable access to development assets (codebases) and that contracts do not put restrictions on adjusting the teams’ work (see Agile Contracts). Also, proactively create learning to enable more teams to flex towards critical types of work.
- Decentralize decision-making. As teams and ARTs run faster, slow decision-making creates its own set of bottlenecks. For example, traditional leaders who have not embraced a Lean-Agile Mindset may struggle with delegating authority. Helping them understand the new way of defining and evaluating work leads to better, faster, and more decentralized decision-making.
#3 Minimize Handoffs and Dependencies
Why it matters
Large systems have many interconnections, making significant dependencies between systems builders common. However, excessive dependencies and handoffs disrupt the flow and create unnecessary context switching and overhead. Delays and cost overruns are typical results.
What to do about it
Although teams cannot eliminate handoffs and dependencies entirely, there are several ways to reduce them at scale, as described below.
- Architect for scale and modularity. Architect large solutions to allow ARTs and teams to iterate independently over designs and release new functionality for feedback with minimal external collaboration.
- Organize around a clearly defined context. Organize ARTs and teams around clear business and technical domains (see Domain Modeling), providing relatively stable organizational structures with fewer dependencies. Apply Team and ART topologies to support this and reduce organizational dependencies.
- Create truly cross-functional ARTs and teams. To create an end-to-end flow of value, ensure every team and ART has sufficient knowledge, resources, skills, and decision-making authority to deliver value with minimal dependencies.
- Organize to support innovation. Since change occurs more frequently in areas of high innovation, organize teams and ARTs around these areas early in the process. As the design emerges, apply the architectural and organizational practices (topologies) described above to decouple ARTs and teams.
- Adopt Lean-Agile practices across the enterprise. Other parts of the organization—such as Procurement, IT, Release Management, and Configuration Management—traditionally work as independent functional departments. This structure, however, can create a silo effect, where work intake procedures do not align with new value delivery opportunities. Instead, introduce the whole organization to the Lean-Agile way of working and include them in ARTs where appropriate.
#4 Get Fast Feedback
Why it matters
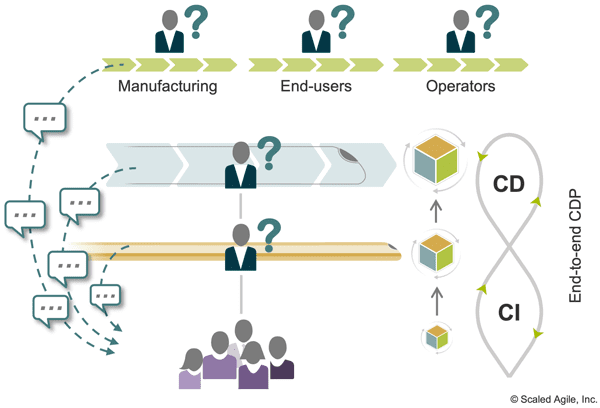
Large solutions often have an unacceptably high cost of failure. Lack of proper feedback during development can lead to massive rework, unanticipated delays, unsatisfied customers, and unacceptable social and economic consequences. However, getting early feedback presents unique challenges for large solution developers. Customers may work in other development value streams or are end-users far removed from the development process. To get their feedback quickly, teams must proactively identify their key customers—end users, other development teams, production, operations, etc.— across an end-to-end delivery pipeline. (Figure 2).
What to do about it
- Find shortcuts to the customer where necessary. Early on, teams must determine who can best provide feedback and proactively break through organizational and other barriers to interact with those customers (Figure 3). Then, by defining personas and journey maps, teams can apply a customer-centric approach to external and internal stakeholders (see Design Thinking). For customers shared across teams and ARTs, create a common set of customer personas and journey maps.

- Ensure capacity for feedback. Getting fast feedback is possible only when others must have the ability to provide it. Confirm that the necessary stakeholders understand the importance of their input and will allocate time to provide it. Likewise, system developers must be able to respond and adjust to the feedback they get.
- Integrate frequently. Getting fast feedback requires the ability to integrate small changes into the larger system quickly. ARTs and teams invest in automating an end-to-end CDP that reduces the time and effort needed to deliver changes for feedback (see Figure 2). And where end-to-end integration is impractical, mockups and digital models help elicit early feedback.
- Build quality in. When developing big systems, minor quality issues within components or subsystems can add up and become major problems for the complete system. Worse, they can be complicated to locate and diagnose, as there are many possible contributing factors, including the simple accumulation of what would otherwise be minor glitches. To address this, ensure that everyone understands the importance of Built-in Quality and provides adequate testing environments for the Solution’s Contexts at all levels (Figure 4).

#5 Work in Smaller Batches
Why it matters
Traditionally, large system builders first specify requirements, design and build the system, test it, and release large batches of new functionality. This restricts flow and delays feedback, resulting in added rework, late delivery, and unsatisfied customers.
What to do about it
- Specify, design, and implement the solution with small, vertically-sliced value increments. Implementing in small batches requires Solution Train leaders to specify and design the system incrementally. Use PI timeboxes to scope new capabilities and exploration activities (See Continually Refine the Fixed/Variable Solution Intent in Enterprise Solution Delivery).
- Focus on critical knowledge creation. To reduce batch sizes, focus Teams and ARTs on what they need to learn from the technical, market, or user-acceptance perspectives. Then converge on the work necessary to gain that knowledge (see SAFe Principle #4, Build incrementally with fast learning cycles).
- Apply a standard cadence across the Solution Train. A shared cadence is a forcing function that helps reduce batch sizes for all contributors. Each PI becomes a ‘pull event’ that gathers small changes to solution elements into an integrated whole for review and feedback.
- Optimize the release batch. Traditionally, large systems are built using a single, significant, and essentially one-time development effort. Conversely, an Agile approach builds the system incrementally, enabling early and frequent releases of value (see Enterprise Solution Delivery). Releasing frequently adds pressure to optimize the release batch. Institute a fast, reliable release process that ensures compliance, allows limited releases to target specific customer segments, and employs a rollback strategy to avoid service disruption when errors occur (see Release on Demand).
#6 Reduce Queue Lengths
Why it matters
Traditional approaches to specifying, designing, and implementing big systems often result in fixed, multi-year schedules, culminating in long, committed queues of unfinished work. These long queues increase wait times for new functionality and inhibit responsiveness to change. While some degree of long-term forecasting and fixed, significant milestones will likely remain, these implied queues of ‘big things yet to do’ must be managed to improve flow time.
What to do about it
- Replace fixed schedules with rolling-wave roadmaps. Wherever possible, replacing fixed plans with connected, rolling-wave roadmaps adds flexibility and agility to system design and delivery. The Solution Train’s roadmap communicates the high-level, rolling-wave forecast of milestones, dates, and Epics that drive connected PI roadmaps for ARTs and suppliers. Roadmaps must be adjusted frequently as new technologies, users, and business facts emerge (Figure 5).

- Apply a set-based design to fixed milestones. Due to the unacceptably high cost of change and the need for coordination (flight test, significant product release, and so on), some milestone dates will likely be fixed and unchangeable. In these situations, apply Set-Based Design to ensure sufficient flexibility in meeting these objectives.
#7 Optimize Time ‘In the Zone’
Why it matters
Large systems have significant scope, complexity, and governance requirements. This creates an environment where ARTs and teams often spend too much time multiplexing, context switching, and reporting — and too little time building the solution. Optimizing time ‘in the zone’ allows practitioners to focus on solution-building without interruption.
What to do about it
- Apply sound system and organizational design. The activities of building large systems can cause teams to spend too much time blocked by technical or business concerns outside their skills, purpose, and mission. Instead, design the system and organizational structures with good separation of concerns, minimize dependencies, and reduce meeting time. This frees the teams to focus on building their part of the work.
- Ensure effective SAFe events. Ensure ART and Solution Train PI Planning and sync events are productive. Reduce or eliminate extraneous and redundant meetings, and manual status reporting activities.
#8 Remediate Legacy Practices and Policies
Why it matters
As a result of their scope, costs, and expected impact, large solution development activities are highly visible and attract significant governance and oversight. Many of these oversight activities are legacy practices that addressed past problems but now create new problems that impede flow. They must be discovered and then either eliminated, modified, or mitigated.
What to watch out for
The examples are many; some are legendary:
- Traditional project and program management models—such as earned value management (EVM), work breakdown structure (WBS), and project-based cost accounting—placed on top of Agile development
- Quality and governance organizations that force waterfall, stage-gated milestones
- Legacy supplier management and contracts that define fixed scope, schedule, and deliverables
- Incentives that encourage people to optimize building their parts of the system versus focusing on the overall system
- Lack of transparency with and across suppliers hiding critical facts until it’s too late to address them
- ‘Color of money,’ politics, or (perceived) legal concerns that prevent the appropriate training and support for suppliers
- Restricted access to the end customers needed to validate the solution
- Engaging verification and validation (V&V) and compliance groups only at the end
What to do about it
Change agents must constantly watch for and recognize these legacy governance rules and practices. In particular, stakeholders in compliance and regulatory functions—such as quality, certification, and release management—may view a Lean-Agile transformation as a risk to their proven approach. Help them obtain the knowledge and information they need to operate successfully in a SAFe development environment by engaging them early and often.
Measure and Improve Flow
And finally, it’s difficult to improve what isn’t measured. Flow is one of SAFe’s three measurement domains (see Measure and Grow) and helps Solution Trains improve by revealing issues and areas for improvement. While all SAFe’s Flow Metrics apply well to the Solution Train, flow time, load, and distribution are particularly relevant and are discussed below.
Flow Time
Building big systems creates a lot of activity, with hundreds or thousands of individuals busy working on their parts of the system. Solution Train leaders must ensure their collective work produces overall value towards a common goal. Flow time measures the interval for solution-level Capabilities and Epics to move through all workflow steps in the Kanban. It shows the ARTs’ and teams’ ability to deliver work against common objectives and is a key indicator that supports planning activities.
The ARTs on a Solution Train have independent work, which ultimately contributes to the overall value of the Solution Train. To ensure all parts of the system are functioning well, Solution Train leaders can track both ART and Solution Train flow time (Figure 6).

Flow Load
As we noted earlier, the need to meet deadlines encourages management to put more work into the system. But this excessive load increases—rather than decreases—flow time. Instead, Solution Train leaders should focus first on completing existing work. One way to understand the load over time is to measure and analyze cumulative flow with a cumulative flow diagram (CFD). This gives leaders insights into how to manage the flow of work better. (Figure 7).

Flow Distribution
Builders of large systems often cannot rely on open-source and out-of-the-box solutions for infrastructure. Even when they can, they must develop even more on their own. Moreover, significant risks abound, and these must be addressed as part of the work backlog. This means that Solution Train leaders must prioritize and balance enabler and risk-mitigation activities with other types of work. Figure 8 shows a flow distribution spanning three types of work items—features, enablers, and maintenance—over a period. Leaders use this information to ensure a healthy balance of the types of work in the system.

Last Updated: 9 October 2023